









 SEO
SEO 13. 5. 2019
13. 5. 2019V minulém roce jsem vydal článek Collabim workflow 1.0 o efektivní práci s nástrojem Collabim. Následující řádky na něj volně navazují, ale vyžadují méně ruční práce. Zároveň se opírá o mnohem lepší podklad pro reporting v Google Data Studio. Potřebujete však znalost OpenRefine a chuť hrát si s daty.
Co se dozvíte?
- Informace o metodice Collabim workflow,
- jak efektivně štítkovat klíčová slova,
- jak interpretovat data v Collabimu,
- jak data napojit na Google Data Studio,
- jak přesvědčit kolegy k využívání Collabim workflow.
Metodika Collabim workflow
Původní Collabim workflow splňovalo hlavní předpoklad, a to jednodušší vizualizaci dat. Ale hodně práce musel odřít specialista / marketér ručně, což činilo systém velmi složitým.
Základem každého projektu v Collabimu jsou klíčová slova, pro které sledujete pozice. V Collabimu však nešlo pracovat s filtry a sledovat data i pozice do hloubky. Jenže právě tyto informace by vás měly při optimalizaci kategorie zajímat. Tento pokročilejší pohled na data mi v Collabimu chyběl, a tak jsem se rozhodl klíčová slova štítkovat. Štítky jsou totiž jedinou věcí, dle níž můžete v různých místech aplikace segmentovat.
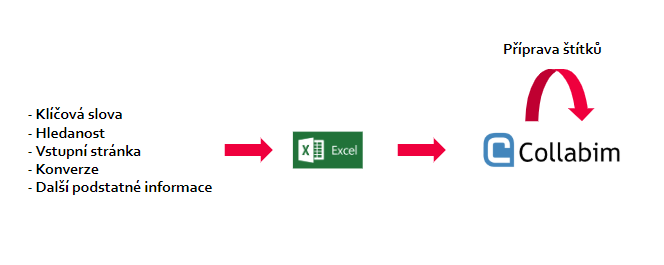
U několikátého projektu mě však vyplňování začalo mnohem víc štvát, než aby mi zjednodušovalo práci. Tudíž jsem se zamyslel a přišel s novým schématem, které obsahuje téměř automatické značkování klíčových slov na základě dat. Také je lépe připraveno na reporting v Google Data Studiu.
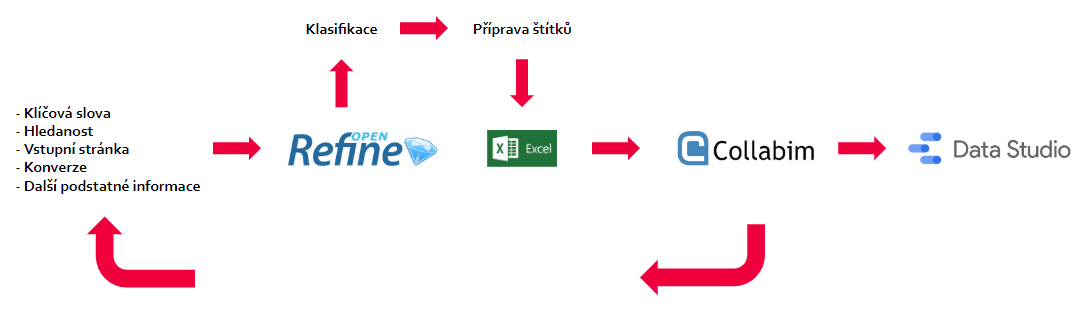
Oproti verzi 1.0 se přidal krok v OpenRefine, kam však při analýze klíčových slov musíme zabloudit všichni. Zároveň přibylo validační schéma, kdy potřebujeme po nějaké době aktualizovat štítky i klíčovku. Nakonec přibyla šipka do Google Data Studia, kde se provádí reporting.
Jak nově štítkuji klíčová slova?
Jak již schéma Collabim workflow 2.0 napovídá, využívám OpenRefine. Slouží mi ke klasifikační analýze klíčových slov, kdy jednotlivá klíčová slova dělím do schémat. Ze schémat a jejich spojení lze jednoduše tvořit štítky a ty pak posílat do Collabimu. Inspiraci jsem našel v klasifikaci klíčových slov pomocí nástroje OpenRefine a jeho funkce facety, jež z klasifikace dělá poměrně jednoduchou záležitost a zábavu.
Klasifikaci využívám zejména k interpretaci dat a vyvození závěrů. To byl také jeden z původních záměrů, proč klasifikaci dělat. Avšak své využití nachází i při skládání štítků pro klíčová slova.

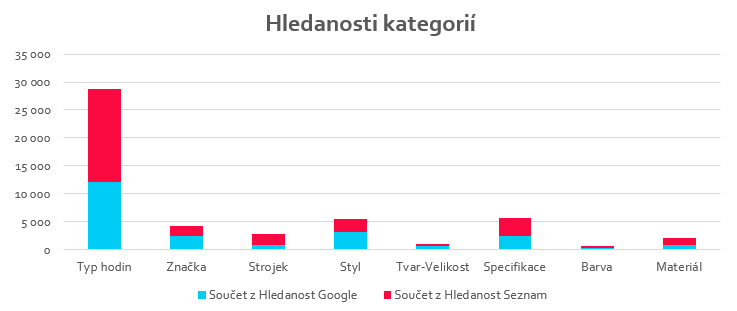
Jestliže neznáte klasifikaci a teď jste chvilku nechápali o čem přesně píšu, tak se podívejte na článek Marka Prokopa, který o klasifikaci psal již v roce 2012. Markův článek o klasifikaci klíčových slov.
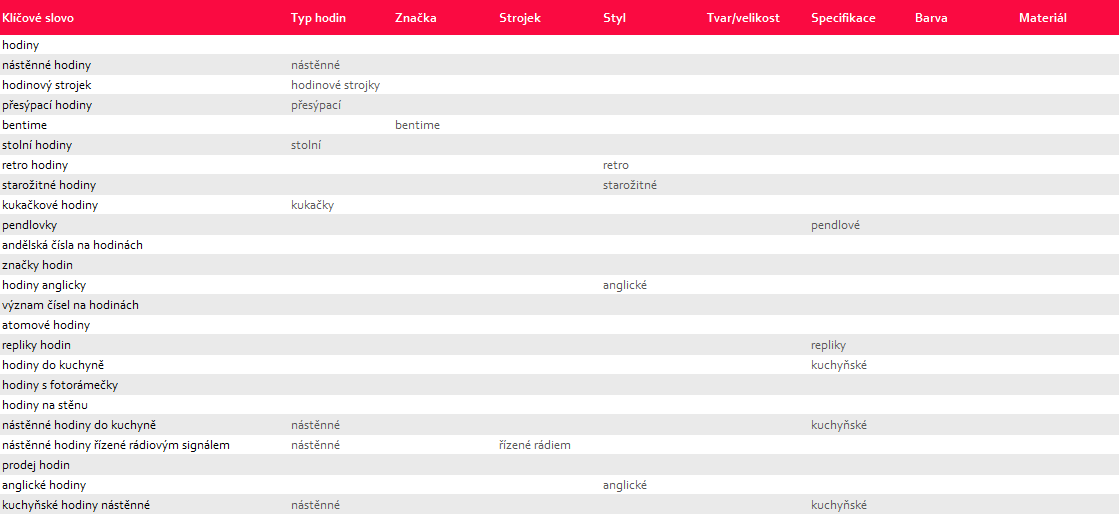
Jestliže uděláte klasifikaci poctivě a jste si jisti daty, které jednotlivé sloupce obsahují, můžete je spojovat do nového sloupečku štítků, které později nahrajete do Collabimu. Tak získáte rozsegmentovanou analýzu.
Pravidla pro skládání sloupců
Při spojování štítků by mohlo dojít k vytvoření variací, a to prohozením pořadí jednotlivých sloupců. Proto si stanovte jasná pravidla toho, jak budete dané sloupce skládat. K tomu je dobré znát jaké varianty se u vás nejčastěji spojují. Pomůže vám jednoduchý přehled v Google Data Studiu.
Do https://datastudio.google.com/s/gQrB_cojWOU stačí naklikat jednotlivé segmenty a hned zjistíte, jaké varianty jsou pro jaké segmenty podobné. Dokážete najít různé vzory, jež následně převedete do štítků. Pamatujte, že vás zajímají pouze ta slova, která se prolínají s nějakým dalším štítkem.
Štítky budete generovat pro každé segmenty, které dané klíčové slovo vlastní. Zároveň je budete generovat i pro společné kombinace těchto segmentů. Pro klíčové slovo: ‚‚designové nástěnné hodiny‘‘ by štítky mohly vypadat následovně: nástěnné, designové, nástěnné+designové. V OpenRefine vytvoříte nový sloupec a v GRELu si pak budete hrát pouze s ifováním a štítky.
if(cells["Schema - 6"].value != null,
value+", "+cells["Schema - 6"].value+",
"+value+"+"+cells["Schema - 6"].value, value)
Jakmile si připravíte sloupeček štítku, tak můžete data vytáhnout do analýzy klíčových slov, jak jste zvyklí, a odevzdat klientovi výstup spolu s tímto novým sloupcem. Až budete chtít nahrát data do Collabimu, využijte importovací nástroj.
Jak na vysoce obsáhlé klíčovky
Jestliže si libujete v analýzách klíčových slov, které mají klidně 10 – 30k výrazů jako my v Taste Medio, vybírejte ty nejrelevantnější pro vašeho klienta, které jsou vysoce oskórované, nebo sekce, jež chcete v následujících měsících vyhodnocovat a měřit.
Při tvorbě štítků se nemusíte omezovat jen na klasifikaci. Můžete využít téměř jakoukoliv metriku k segmentování klíčových slov. Co by mohlo být zajímavé a standardně v analýze klíčových slov máte: relevance KW, konkurenčnost, cenové hladiny v PPC nebo konverznost v placených kanálech. Tyto i další informace lze jednoduše posílat do štítků a následně s nimi pracovat a v Collabimu segmentovat.
Unikátností tohoto řešení je, že když si OR projekt zálohujete na disk a budete chtít v budoucnosti provést aktualizaci štítků, tak díky historii příkazů o možnost nepřijdete a budete moci jednoduše upravit onen krok se sestavením štítků.
Interpretace dat v Collabimu
Díky štítkům v Collabimu se vám otevřou nové možnosti v grafech. Také získáte mnohem lepší přehled o tom, jak se vaše činnost vyplácí a zda přináší ovoce. Např. když se domluvíte s klientem, že budete v následujících měsících pracovat na sekci ‚‚nástěnné hodiny‘‘, měli byste vidět v grafech růst. Jestliže se on-page či off-page změny nepropisují v dlouhodobějším horizontu, pravděpodobně děláte něco špatně.
Pokud neoštítkujete klíčová slova, vždy se díváte na celý dataset. Ten může čítat klidně 1 500 – 7 500 klíčových slov, ale často se zaměřujete jen na pár kategorií / stránkách. Případné změny změny budou tedy na celém datasetu nedoměřitelné a minimální, proto je lepší dívat se na štítky.
Rozložení pozic klíčových slov
Vaším cílem by mělo být dostat co nejvíc klíčových slov z červené zóny (21+) do dalších zón. Nejlepší je, když se co nejvíc dotazů nachází v TOP3. Optimálně sledujte vždy kategorie, na kterých pracujete, protože na velkém datasetu onen vývoj nemusíte vidět nebo bude pouze minimální.

Market share na první stránce vyhledávání
Často se setkávám s klienty, kteří si nevyplnili záložku konkurence. Neznají tedy informace o své pozici vůči jejich přímé konkurenci. Jakmile si však všechny konkurenty vyplníte, tak máte možnost sledovat následující graf. V něm zjistíte, jak rostete na první stránce výsledků vyhledávání.
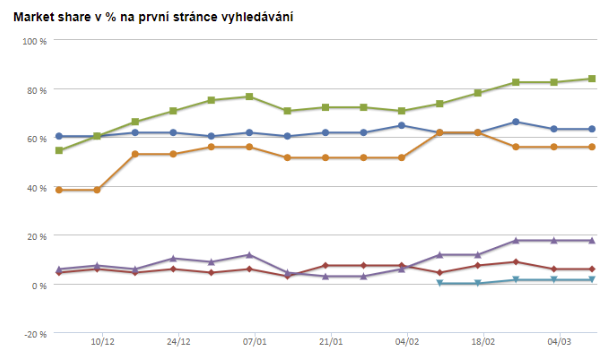
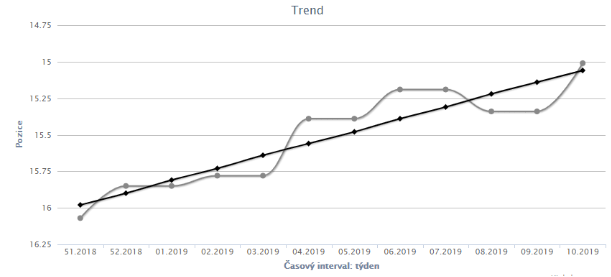
Historie klíčových slov a graf trendu
Další zajímavý přehled představuje sledování vývoje v historii klíčových slov a sledování trendu vašich SEO aktivit. Na šedivé křivce vidíte, jak se vyvíjí vaše pozice a jestli rostete, zatímco na černé přímce se pak znázorňuje trend vašich SEO aktivit. Jakmile dlouhodobě pracujete na nějakém projektu a kategorii, trend by měl být pozitivní.
Bussines data a návštěvnost
Na informacích z Collabimu mi chybí pohled na dopad výsledků v Google Analytics nebo Google Search Console jako návštěvnost, imprese, kliknutí a plnění cílů. Všechna data lze jednoduše vytáhnout pomocí API do Google Data Studia, ukážu vám, jak na to.
Napojení do Google Data Studia
Google Data Studio obsahuje konektory na Collabim. Podrobnosti o nich se dozvíte v dokumentaci Collabimu. Také k nim vzniklo popisující video o tom, jak s konektory pracovat:
Abyste z Collabimu dostali data, která potřebujete, budou se vám hodit tyto konektory:
- KW positions (from-to) – pozice klíčových slov (od, do)
- KW positions (lastXDays) – pozice klíčových slov, posledních X dní
- Market share – aktuální rozložení
- Market share history (from-to) – historie
- Market share history (lastXDays) – historie, posledních X dní
- Average keyword positions (lastXDays) – průměrná pozice, posledních X dní
- Average keyword positions (from-to) – průměrná pozice, od-do
Zde je jedno velké omezení – můžete tahat data pouze za předem určené dny, které nastavujete v konektoru napevno (lastXDays). Stejně tak si musíte správně nastavit i Google Analytics, aby obě osy x byly stejné. Výsledné grafy v Google Data Studio mohou předávat vašim kolegům všechny podstatné informace na jednom místě. Když budete hodně šikovní, tak můžete data tahat ven a využívat například PowerBI nebo Tableau.
Jak do práce zapojit kolegy?
Workflow funguje pouze v případě, kdy do práce zapojíte všechny kolegy, kteří se věnují tvorbě nových stránek, textů nebo optimalizaci. Tím, že dostanete data z Collabimu do svého reportovacího systému, můžete pomoct lidem přijmout tento způsob evidence klíčových slov.
Každý chceme přeci dělat smysluplnou práci a zároveň vidět výsledky. Díky Collabim workflow 2.0 to bude ještě snazší než předtím. Možná, že vás odstraší ona procedura v OpenRefine, ale vždyť tým může klasicky využívat Google Sheets a ta data můžete do Collabimu nahrávat přes Refine vy.
Ať už se rozhodnete využívat novou nebo starou verzi workflow, rozhodně si tím ulehčíte práci s reportingem a dokazováním výsledků. Uvidíte přesně, jak se vaše kategorie vyvíjí a jestli děláte optimalizaci pro vyhledávače dobře.




