









 SEO
SEO 15. 5. 2019
15. 5. 2019Jeden z nejčastějších omylů, kterého se dopouští i zkušení SEO harcovníci, je využití standardu robots.txt pro zákaz indexace stránek:
|
1
2
|
User-agent: *
Disallow: /
|
Zapamatujte si jednoduché pravidlo. Robots.txt neslouží k zákazu indexace stránek. Nikdy a ani trochu. A naopak může uškodit.
Indexace versus crawlování
Pro pochopení je nutné znát rozdíl mezi crawlováním a indexací. Crawlování znamená, že se robot vyhledávače prochází po vašem webu a stahuje si k sobě od vás jednotlivé stránky pro další zpracování.
Indexace je pak sestavování indexu – tedy databáze, ve které fulltext po zadání dotazu hledá. Do indexu přitom zařazuje stránky a informace o nich získané nejen z crawlování, ale i z dalších zdrojů, které vyhledávači přijdou zajímavé a užitečné.
Typicky už jenom tím, že se na nějakou konkrétní stránku odkazuje odjinud, dostává vyhledávač o dané stránce řadu zásadních informací – link text odkazu, klíčová slova v její URL, tematický kontext, ze kterého se na ni odkazuje, podobu a sílu jejího odkazového profilu. Další údaje může získat z popisků či kategorií v katalozích, do kterých je stránka zařazena. A tak dále.
Co je na zákazu indexace přes robots.txt špatně?
Robots.txt nezakazuje zařazení dané stránky do indexu, ale jen a pouze její crawlování robotem vyhledávače. Říkáte tím tedy, že si na danou URL nesmí crawler přímo sáhnout a stáhnout si k sobě její obsah.
Vyhledávače si ale i nadále můžou zařadit stránku do indexu jen na základě dalších údajů z jiných zdrojů a nabízet ji ve výsledcích hledání. A skutečně to velice často dělají:
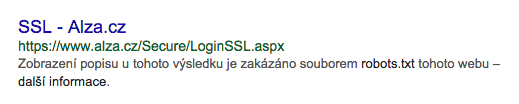
Je vidět, že informace, které Google o stránce na SERPu zobrazuje, nepochází ze samotné stránky, ale právě z nějakého link textu a dalších zdrojů v okolí dané stránky. Všimněte si, že vyhledávač uživatele upozorní, že o stránce má jenom dílčí neúplně informace. Ale i přesto ji indexuje, nabízí a zobrazuje.
Jak tedy správně zakázat indexaci?
Správný zákaz indexace závisí na kontextu a důvodech, proč to vlastně vůbec chcete dělat:
Link rel=canonical
V případě, kdy máte na webu duplicity nebo silné podobnosti, které nelze vyřešit sloučením všech stránek v jedinou a přesměrováním ostatních přes HTTP 301, je místo zákazu všech duplicitních variant lepší použít meta značku canonical:
|
1
|
<link rel=“canonical“ href=“http://www.example.com/my-canonical-page“/>
|
Nejedná se o zákaz indexace v pravém slova smyslu, ale spíš o nezávaznou nápovědu vyhledávači, kam by měl všechny duplicitní a podobné stránky kanonizovat. Výhodou je, že pokud na to vyhledávač přistoupí, koncentruje do navržené kanonické stránky odkazy a rank ze všech takto označených stránek. Nevýhodou je, že to vyhledávač nemusí vůbec respektovat.
Meta robots noindex
Tohle je ta správná, čistá a bezpečná metoda, jak skutečně zakázat indexaci dané stránky. Do její HTML hlavičky přidáte meta značku:
|
1
|
<meta name=“robots“ content=“noindex“/>
|
Využijete to v případě stránek, na které vůbec nechcete, aby vám uživatelé chodili z vyhledávačů napřímo. Typicky třeba kroky nákupního procesu nebo děkovací stránky po odeslání konverze. Čistě pro jistotu i všechny stránky s nějakými neveřejnými citlivými údaji, i přesto, že ty máte určitě všechny dávno schované za přihlášením.
Po meta robots noindex sáhnete i v případě, kdy se reálně potýkáte s duplicitami či podobnostmi, ale vyhledávač odmítá zohlednit navržený meta canonical. Nevýhodou je, že se vám pak rank tematicky nekoncentruje v ideální kanonické stránce, ale rozplizne se vám bezkontextově přes všechny odchozí odkazy do zbytku webu.
HTTP hlavička X-Robots-Tag
Alternativa k meta robots noindex. Jenom místo HTML zdrojáku se posílá přímo v HTTP hlavičkách v HTTP odpovědi od serveru:
|
1
2
3
4
5
|
HTTP/1.1 200 OK
Date: Tue, 25 May 2010 21:42:43 GMT
(…)
X-Robots-Tag: noindex
(…)
|
Čili v zásadě totéž jako meta robots noindex. Jenom je to složitější na implementaci – HTML tag vrazí do zdrojáku každý, HTTP hlavičky už jsou vyšší dívčí. A navíc písmeno X na začátku naznačuje, že je to nestandardní HTTP hlavička, takže nemusí být podporovaná zdaleka všemi vyhledávači. Takže meta robots noindex bude asi většinou lepší variantou.
Více viz článek Robots meta tag and X-Robots-Tag HTTP header specifications.
HTTP autentizace
Zejména pro testovací verze vyvíjeného webu se místo zákazu indexace hodí skrýt paušálně celý web za HTTP autentizaci. To se zapíná obvykle přímo v konfiguraci daného webového serveru. Testovací verze webu se schová za heslo, takže na ni nevidí nikdo nepovolaný. Vedlejším efektem pak je, že je chráněna i před nechtěným zcrawlováním a indexací vyhledávačem.
Čistě formálně vzato, stejně jako u robots.txt platí, že ani HTTP autentizace přímo nezakazuje indexaci, jenom se crawler nedostane k samotným stránkám. U testovací verze webu se ale neočekává, že by měla nějaký smysluplný odkazový profil a vnější kontext, ze kterého by mohl vyhledávač čerpat další informace. A i kdyby ji nějakým omylem zaindexoval, tak příchozí návštěvníci z vyhledávače narazí nanejvýš tak na přihlašovací formulář. Takže pro náš účel poslouží HTTP autentizace zpravidla uspokojivě.
Výhodou je i to, že po překlopení webu na ostrou doménu se často meta robots nebo robots.txt zákazy zapomínají odstranit, takže vedou obratem k vypadnutí celého webu z indexu vyhledávačů. U HTTP autentizace je riziko nechtěného zapomenutí minimální.
Pozor na chybné kombinace
Teď už víte, že pro zákaz indexace slouží primárně meta robots noindex. Možná vás napadne, že pro jistotu to stejně navíc podpoříte současným zákazem v robots.txt. Čistě pro sichr, co kdyby, za to nic nedáte.
To je ale přeci úplně špatně! Jen si to srovnejte v hlavě. Tím, že robotovi zakážete přistupovat na vaše stránky, nemůže si stáhnout HTML zdroják, takže se ani vůbec nedozví o tom, že tam nějaký meta robots noindex je. V důsledku paradoxně může tyto stránky vesele indexovat a nabízet ve výsledcích hledání.
Robots.txt prostě opravdu nesmí být u zákazu stránek ani trochu.
Obdobně doprovodí řada lidí meta robots noindex ještě dalším parametrem nofollow. Přeci čím víc zákazů, tím jistější:
|
1
|
<meta name=“robots“ content=“noindex,nofollow“/>
|
Ve skutečnosti tím ale zakážete následování interních odkazů ze stránky dál a dost možná i přelévání ranku do zbytku webu. Vytvoříte tak černou díru na rank, což se vám může promítnout do nižších pozic obecně celého webu. Ale vy chcete zachovat a předat co nejvíce ranku, chcete, aby robot snáze objevil indexovatelný zbytek vašeho webu. Správný zápis je tedy:
|
1
|
<meta name=“robots“ content=“noindex,follow“/>
|
S tím, že follow je výchozí hodnota, takže ji můžete úplně vynechat. Nofollow smysluplně použijete opravdu tak jednou za sto let.
A k čemu tedy v praxi využiju robots.txt?
Zůstává otázka, k čemu tedy vlastně robots.txt je, když ne k zákazu indexace.
Je přesně k tomu, k čemu byl navržený. Tedy pro zákaz přímého přístupu robota na web nebo nějakou jeho dílčí stránku. To se občas hodí, sic zdaleka ne tak často, jak jste si mysleli.
Například pokud máte URL, jehož pingnutím se hlasuje v nějaké anketě, a nechcete, aby vám roboti při procházení vaším webem přičítali hlasy. Totéž platí pro jakékoliv trackovací a přesměrovací skripty, například pro počítání návštěvnosti nebo prokliků z reklamního systému:
|
1
2
3
|
User-agent: *
Disallow: /poll/vote
Disallow: /clickthru
|
Roboty budete chtít někdy zakázat také z výkonnostních důvodů. Ať už na dílčích skriptech a stránkách, jejichž každé zobrazení představuje složitý výpočet náročný na serverové zdroje či vám prostě přijde zbytečné, aby si je vyhledávač stahoval:
|
1
2
|
User-agent: *
Disallow: /overkill-page
|
Anebo třeba přes robots.txt můžete paušálně odříznout nějakého konkrétního robota, pokud je neukázněný a sestřeluje vám web:
|
1
2
3
4
5
|
User-agent: badbot
Disallow: /
User-agent: *
Disallow:
|
Pořád jenom roboti. A co lidi?
Aby to bylo spravedlivé, máme tu pro zájemce jako bonus na závěr i standard humans.txt.
Tento článek byl zveřejněn 27. 1. 2015 na Medio Blogu. Taste Medio je dnes součástí skupiny Taste.




