









 SEO
SEO 14. 12. 2023
14. 12. 2023Jazykové modely Large Language Models (LLM) jsou významným pokrokem v oblasti umělé inteligence a strojového učení. Od prvních pokusů o simulaci lidského jazyka a porozumění textu se tyto modely vyvinuly do úchvatné podoby. Nyní jsou už schopné nejen rozumět textu a generovat vlastní texty, ale také provádět složité úlohy, jako je překlad jazyků, shrnování textů nebo jejich interpretace.
Vývoj LLM začal jednoduššími modely založenými na statistických metodách a postupně přešel k pokročilejším technikám, jako jsou neuronové sítě. Důležitý zlom nastal v posledních letech, kdy modely jako GPT (Generative Pre-trained Transformer) od OpenAI dokážou kombinovat obrovské množství dat a pokročilé algoritmické techniky pro generování textu s cílem vrátit co nejpřesnější odpověď.
Tyto modely mají široký rozsah použití – od asistování v psaní a editaci textů přes automatizaci zákaznického servisu až po výzkum a vzdělávání. Jejich schopnost zpracovávat a generovat text v lidském jazyku otevírá nové možnosti v mnoha oblastech, včetně podnikání, vzdělávání, nebo dokonce umění.

Úvodní fotografie labyrintu ke článku řešící efektivní využití kontextu jazykových modelů
Silné GPT-4 Turbo s odkazem minulosti
Model ChatGPT-4 Turbo je aktuálně nejnovější a nejpokročilejší přírůstek v rodině jazykových modelů Large Language Models (LLM). Přináší významné zlepšení v oblasti zpracování a generování jazyka, nabízí rozšířené kapacity a je optimalizován pro vyšší ekonomickou efektivitu.
Model ChatGPT-4 Turbo má konkrétně tyto výhody:
- Zpracovává až 128 000 tokenů na vstupu, což může být i 300 normostran textu. Velkou roli zde ale hraje vstupní jazyk dokumentu, který znatelně ovlivňuje výpočet použitých tokenů.
- Model má rozšířenou znalostní bázi do dubna roku 2023. Jedná se tedy o pomocníka s aktuálními informacemi ze současného světa, a především s aktuálními znalostmi, které lidstvo posunuly zase o krůček vpřed.
- Cenovka API GPT-4 Turbo je na vstupu 3x levnější než u předchozího modelu GPT-4. Vstup si můžete představit jako vaše zadání, které píšete to běžného chatu. Cena za odpověď, kterou vám model v tomto chatu vrátí je 2x levnější než u modelu GPT-4. Z API pro model GPT-4 Turbo to tak dělá mnohem atraktivnější a dostupnější variantu, která podpoří vývoj aplikací a celkovou dostupnost modelu pro komerční využití.
Nicméně než se plně ponoříme do světa GPT-4 Turbo, je důležité odbočit a podívat se na studie předchozích modelů, které odkrývají určité problémy spojené s LLM. Jedním z hlavních problémů, který byl identifikován, je ztráta informací v textech s velkým kontextem.
Studie jako Lost in the Middle poukazují na to, že modely LLM mají tendenci zachytávat informace efektivněji na začátku nebo na konci dlouhých textových sekvencí. Naopak informace umístěné uprostřed takových sekvencí mohou být přehlíženy, nebo dokonce ztraceny. Tento fenomén má významný dopad na schopnost modelů přesně interpretovat a sumarizovat dlouhé texty, a to je samozřejmě naprosto klíčové pro jejich efektivní využití v praxi.
V následující části se na tuto studii podíváme blíže. Na konci se pak pokusím přidat doporučení, jak s modelem GPT-4 Turbo pracovat, abyste získali detailnější a přesnější výstup.
Studie Lost in the Middle
Studie Lost in the Middle zkoumala, jak jazykové modely využívají dlouhé kontexty. Využila k tomu řízené experimenty s řadou moderních otevřených a uzavřených modelů. Tyto modely zahrnovaly MPT-30B-Instruct, LongChat-13B (16K), OpenAI GPT-3.5-Turbo a Anthropic’s Claude-1.3.
V tomto experimentu byl zahrnut i model GPT-4, který explicitně zmiňuji, protože využívá stejnou technologii a architekturu jako model GPT-4 Turbo. To naznačuje, že problémy budou u obou modelů velmi podobné, pouze u Turba budou na delším kontextovém okně.
Nicméně tento model nebude zahrnut ve výsledných grafech, protože probíhal na menším vzorku testovaných dat z důvodu vysoké ceny testování. Výsledky tohoto modelu však vykazovaly velmi podobné tvary grafu jako ostatní modely LLM.
Jak probíhalo testování?
V této studii byly modely LLM vystaveny úlohám zahrnujícím více dokumentové otázky a odpovědi, což jednoduše znamená simulování zpracování informací z více zdrojů pro odpověď na konkrétní otázku. Kromě toho byly modely testovány pomocí syntetických úloh klíč-hodnota, kde musely modely získat odpovídající hodnotu pro specifický klíč z kolekce JSON-formátovaných klíč-hodnota párů.
V obou případech byly experimenty koncipovány tak, aby umožnily kontrolované změny v délce vstupního kontextu a v pozici relevantních informací. Tento prvek byl žádoucí pro přesné měření výsledků.
Ve výsledku se zjistilo, že výkon modelů je nejvyšší, když hledané informace jsou na začátku nebo konci vstupního kontextu. Tento výkon ale výrazně klesá, když musí přistupovat k informacím umístěným uprostřed dlouhého kontextu. Lépe si propady v přesnosti představíte pomocí následujících grafů, kde se první tři grafy věnují vícedokumentovému testování.
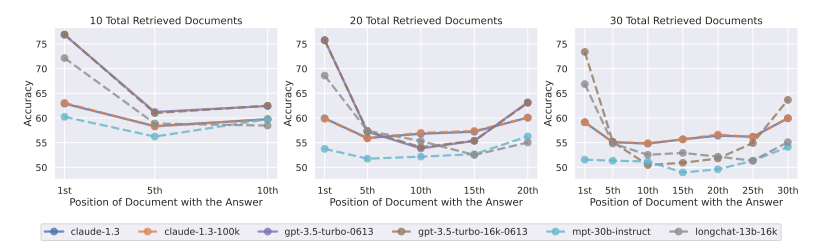
Graf z vicedokumentového testování ze studie Lost In The Middle-4 turbo
- Horizontální osa (X-osa): Udává pozici dokumentu s odpovědí ve skupině načtených dokumentů. Čísla jako 1st, 5th, 10th až 30th označují pořadí dokumentů, ve kterém byla nalezena odpověď.
- Vertikální osa (Y-osa): Zobrazuje procentuální přesnost (Accuracy) modelu při hledání odpovědi. Hodnoty na této ose ukazují, jak často byl model schopen správně identifikovat a extrahovat odpověď z dané pozice dokumentu.
Grafy ukazují tři různé experimenty s 10, 20 a 30 načtenými dokumenty, kde byla délka finálního dokumentu přizpůsobena danému modelu. Linie různých barev představují různé jazykové modely, včetně Claude-1.3, Claude-1.3-100K, gpt-3.5-turbo-0613, gpt-3.5-turbo-16k-0613, mpt-30b-instruct a longchat-13b-16k.
Můžete na nich dobře vidět, jak přesnost klesá, pokud je relevantní informace dále od začátku a bližší k prostředku načtených dokumentů. Tento trend je konzistentní napříč všemi třemi experimenty, což poukazuje na globální problém jazykových modelů, který se netýká pouze modelů od OpenAI.
Formátované testování JSON key-value
Nyní se podívejme na druhý typ testování modelů v rámci studie Lost in the Middle. To se zaměřilo na syntetické úlohy klíč-hodnota. Tento minimalizovaný testbed byl navržen k posouzení základní schopnosti modelů správně načítat a přiřazovat odpovídající hodnoty ke konkrétním klíčům z kolekce JSON-formátovaných párů.
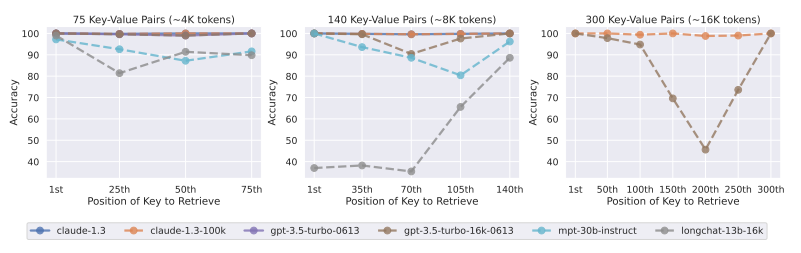
Graf z key-value testování ze studie Lost In The Middle
Na grafu vidíte výsledky v procentuální přesnosti (Accuracy) modelů LLM při vyhledávání hodnot v klíč-hodnota párech. Model Claude-1.3-100K vykazuje konzistentně vysokou přesnost napříč všemi kontexty. Má tedy schopnost zpracovat a udržet informace v kontextu do 16 000 tokenů.
Dá se tak předpokládat, že GPT-4 Turbo, který má větší kontextové okno a pravděpodobně vyspělejší architekturu, by měl být schopen dosáhnout podobně vysoké úrovně přesnosti, ne-li vyšší přesnosti v krátkých kontextech do 32 000 tokenů.
Kdo lépe zpracuje text?
Pojďme se podívat na menší studii modelu GPT-4 Turbo od tvůrce s twitterovou přezdívkou @swyz, který se specializuje na vývoj menších jazykových modelů. Jeho původní příspěvek si můžete najít na adrese příspěvku. V této studii použil podobnou metodu klíč-hodnota, kde bylo cílem najít deset specifických informací v rozsáhlém textu. Tento test můžete přirovnat k hledání jehel v kupce sena. Test porovnával modely GPT-4 a GPT-4 Turbo, přičemž GPT-4 Turbo vykázalo výrazně lepší výsledky na kontextech do 32 000 tokenů než jeho předchůdce.
GPT-4 Turbo ve srovnání s původním modelem GPT-4 přineslo značné zlepšení ve zpracování textů:
- Na 8 000 tokenech vykázalo 1,9násobné zlepšení.
- Na 16 000 tokenech dokonce 3,5násobné zlepšení.
- Na 32 000 tokenech stále velmi slušné 2,4násobné zlepšení.
Kompletní výsledky přesnosti jednotlivých modelů si můžete prohlédnou v tabulce níže:

Graf ze studie z Twitteru od tvůrce swyz
Tyto výsledky ukazují výrazný pokrok v efektivitě a přesnosti sumarizace u GPT-4 Turbo v porovnání s původním modelem GPT-4.
To pak otevírá dva přístupy k použití GPT-4 Turbo:
- Pokud chcete získat detailní informace z analyzovaného dokumentu, je třeba ho rozdělit do logických celků, například do jednotlivých kapitol, které shrnují jedno téma. V tomto případě se snažte držet kontextové okno ideálně do 16 000 tokenů.
- Pokud chcete získat hlavní myšlenky z velmi dlouhého dokumentu, kde nelpíte na detailech, je možné využít celé kontextové okno 128 000 tokenů. V tomto případě využije model své schopnosti pro sumarizaci textu a bude se snažit zachytit několik hlavních myšlenek, které poté vrátí.
Na lepší výsledky si ještě počkáme
Studie jako Lost in the Middle ukazují, že současné jazykové modely mají stále prostor pro značné vylepšení. Přestože dosahují impozantních výsledků, zejména v kratších kontextech, jejich schopnost zpracovávat dlouhé texty s vysokou přesností je omezená.
Opravdu perfektní výsledky od jazykových modelů tedy můžeme očekávat teprve v budoucnosti, jakmile dojde k dalšímu vývoji a vylepšení těchto technologií. Pokračující výzkum a vývoj nám v konečném důsledku umožní využít plný potenciál jazykových modelů v široké škále aplikací. A teprve to možná přinese tu pravou transformaci trhu.




